
by J.M. Vanel , Copyright © J.M. Vanel - 2001
Last update:Download current version; User documentation ; en français
It uses cutting-edge XML techniques and particularly XSLT. It is under GNU Public License.
I used these techniques for industrial catalogs at industrySuppliers.com, a (defunct) market place, last spring. Then I got involved in Seed to Seed (www.seed2seed.net), a project to publish information collected worldwide about sustainable agriculture. With a bit of refactoring, XML Publication resulted from these projects. Someday XML Publication will also be applied to Worldwide Botanical Knowledge Base .
Source a table, a paragraph structured text, a poorly structured word processor file, etc.
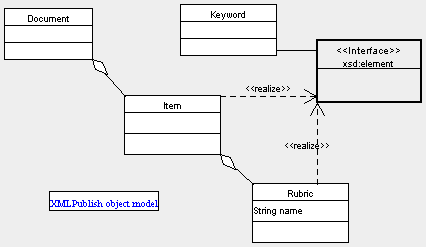
| If your browser is an SVG browser (like Amaya), you see below an UML
diagram of XMLPublish Information object model:
Otherwise, use these links: XMLPublish object model as SVG (if you have the Adobe SVG plugin) |
Simple 2-level structure reflecting the above "Information object model" :
<root> <itemType1> <rubricType1>any markup ...</rubricType1> <rubricType2>any markup ...</rubricType2> ... etc </itemType1> ... other item types </root>
Historically in XMLPublication there were 2 concrete structures for the master.xml file:
but now there is just one: documents with paragraphs and sub-paragraphs. Here is a sample:
<div class="h1" > <h1>Item name</h1> <div class="h2"> <h2>Rubric name</h2> Rubric content </div> ... </div>
Currently we use <p> tags for wrapping items and rubrics, but will switch to <div> in a next version, because <p> as a wrapper is not valid with respect to the HTML DTD. This markup should pass intact through most of the HTML tools (testers wellcome !).
Note 1: ideally the tidy operation for this feature should be idempotent (an algebraic operation x is said idempotent if x is such that xx=x).
Note 2: The ISO/IEC 15445:2000 norm about HyperText Markup Language (HTML) also has a spec. for wrapping paragraphs, but is is through div1, div2 tags that are not in the W3C standard. See http://www.cs.tcd.ie/15445/UG.html .
mode
matching a smaller subset of of items or rubricsAutomatic update and chaining with GNU Jakarta Ant (or GNU make).
Moreover ant allows to be multi-platform regarding file-systems.
The build.xml files are designed so that data can be URL, not only files (alas Ant is not yet enough Web-oriented, but we work on that too).
This is done in publication-magician.xslt . The starting point is the work/master.xml file which aggregates all document sources; it has the structure described above (XML basic structure).
// make a unique list of rubrics across document sources: for each unique string in: $master.xml/p/p/h2 store it in a new <rubric> element // for each rubric make a list of occuring words Loop on rubrics Concatenate words for this rubric from all items Tokenize to get each word wrapped in an XML element Sort and suppress doubles in words list Filter words list (upper/lower case, numbers, etc) Mark stopwords Write <rubric> with sub-element <keyword>
This is done in make-index-by-rubrics-impl.xslt
. It has some parts similar to preceding stylesheet, and would need some
refactoring . This is because when user chooses <rubric
use-keywords="no" > , it does the same thing as preceding
stylesheet, just keeping <rubric> element in a <xsl:variable>
instead of writing it in publication.xml .
Loop on rubrics
Fill HTML document for this rubric
Loop on words list
Loop on items
If word is found in this rubric of this item
add hyperlink to HTML item file
Fill HTML document for the overall index.html
Loop on rubrics
add hyperlink to HTML document for this rubric
Each functionality in a separate XSLT transform:
The chaining of transforms (data-flow) is not hard-wired in the XSLT
transforms, the Ant build.xmltakes care of that.
{kind=link}
{kind=link}